
Resolution Code
Resolution Code is a system for converting between shapes and text.
With the great variety of writing systems, fonts, and lettering styles in existence, there is a wide range of shapes that have the ability to represent language. And yet most shapes — even rather simple ones — do not represent language in any system. What if there were a system in which every possible shape represents language?
This question first prompted me to design Contour Code. My original hope with Contour Code was that it could be used to assign meaning to any shape in one’s environment. However, I soon realized that it only works for crisp geometric shapes; most shapes from the real world are too rough or complicated for it to handle. I set out to create a more flexible system that can interpret a fractal just as easily as it interprets a circle. Resolution Code can do this, and it can also encode any given text into a shape, which will usually end up being a fractal.

The Universal Declaration of Human Rights, encoded in a recent version of Resolution Code
Resolution Code represents a shape using a sequence of images at higher and higher resolutions: first 2×2, then 4×4, then 8×8, and so on to infinity, doubling each time. The system represents each of these images as binary digits and appends the digits to an ever-growing string, which can be interpreted as text using a binary text encoding. However, rather than appending the bits for the whole image, it only records the parts that have gained detail since the last iteration: the pixels at the edge of the shape, which are divided into four smaller pixels that represent the edge with more detail. All the other pixels give no new information since the last iteration and don’t need to be written down. The resulting string of binary digits can be used to reconstruct the shape at an arbitrarily high level of detail.
To this core idea I have been adding refinements:
- The system also works the other way, to input text and output a shape. To ensure that the output actually looks like a shape, and not just a set of squares stuck to each other, I imposed some conditions on how each pixel is allowed to be subdivided depending on the pixels touching it.
- These conditions had the side effect of greatly increasing the amount of negative space, creating a light dusting of specks instead of bigger shapes. To counteract this, I apply another encoding to the beginning of the sequence to weight it more heavily with ones over zeros, as that creates more positive space.
- To be interpreted by Resolution Code, a shape first needs to be put in a square frame. There are many possible ways to frame a shape, each of which would result in different text. I added a rule that delineates a single way to frame every image, and adjusted the shape generation process to ensure it only produces shapes framed in this way.
- Currently, interpreting an arbitrary shape will invariably result in gibberish text. I am considering how I might use a machine learning model to weight the system so it is more likely to produce meaningful language.
I think the easiest way to understand how the system works is to understand the design process behind it, so it makes sense why each new complication is necessary. In the description below, I walk through the process in this way, giving the necessary background for those with no prior knowledge of graphics or encoding systems.
Explanation and design process
My goal was to create a process with the following properties:
- You can give it any possible text and it will produce a shape
- You can give it any possible shape and it will produce text
- If you convert some text into a shape, and then convert that shape to text, it will be the same text you started with
- If you convert a shape into text, and then convert that text to a shape, it will be the same shape you started with
Or in mathematical terms, a bijection between texts and shapes.
Background concepts and exploration
The basic idea is to break the text down into characters, then use some system to interpret these characters as a description of a shape. But “a description of a shape” is rather vague. There are many ways to describe shapes. For example, consider this shape:

You could describe it using several methods:
- Construct it from simpler shapes: “An overlapping square and circle of about equal size, with the circle covering the bottom left corner of the square.”
- Give instructions for drawing the outline: “Starting from the top right corner, draw a line that is 2 units long and headed down, then a line 1 unit left, a clockwise arc from 3:00 to 12:00 with a radius of 1 unit, a line 1 unit up, and a line 2 units right.” (This is the strategy I used with Contour Code: it would read this shape as a sequence of straight edges and one convex edge.)
- Mathematically define a set of points on a coordinate plane: “A shape composed of all the points that are either within 1 unit of (0, 0) or that have both x and y coordinates between 0 and 2.”
- Approximate it with a pixelated image: “Set up a 300×300 grid of pixels. From left to right and top to bottom, the pixels are colored as follows: white, white, white, white, white… (repeated many times) …white, white, black, black, black, black, black… (repeated many times) …black, black, white, white, white, white, white… (and so on for all 90,000 pixels).”
What kind of method do we want to use in this system? Recall that the goal is to be able to describe any shape, including complicated natural shapes like this:

Some types of description are better for this than others. Constructing it from simple geometric shapes (1) wouldn’t really work, since it’s not composed of such shapes. Describing how to draw the outline (2) also wouldn’t work very well — the outline is so rough that it would take a huge number of fine-grained steps to even start to approximate it, and there’s no good way to decide on one approximation over another. Giving a mathematical definition (3) isn’t good because the shape doesn’t conform to any simple mathematical function.
Using pixels (4), however, works great. (That’s how this webpage does it.) So let’s say that our encoding process will describe a shape as a grid of pixels, each of which can either be black or white. (Of course shapes don’t have to be black and white — it would be more accurate to say figure/ground or inside/outside, but throughout this description I’ll say black/white for simplicity.) Therefore our goal is to create a process that inputs some text and outputs a list of black/white pixels that can be put together into an image.
One way to do this is to convert the text to Morse code, and then say that a dot becomes a white pixel while a dash becomes a black pixel. For example, “word” in Morse code is
.-- --- .-. -..
which converts to this sequence of pixels:

We can then arrange these pixels into the rows of a (very low resolution) image, like this:

That worked fine, but there are some issues with this approach. First, why arrange them into a 4×3 image, and not a 3×4 image? We could just as well have made the following image out of the same sequence of pixels:

In this system for converting from text to images (I wouldn’t really call this a “shape” yet) we have to make an arbitrary choice for what image dimensions to use. But part of the goal is to create a system that has exactly one way to encode any text into an image. If there are multiple ways to convert from text to image — as there are when the dimensions aren’t set — then it isn’t possible to unambiguously convert from image to text and back. If you convert an image to text, you give someone else the text, and they convert that text into an image, they might get the wrong image because they have no way of knowing what dimensions they were supposed to use.
Also, the way we’re using the code is ambiguous. Morse Code relies on pauses or spaces to indicate when one letter ends and the next begins, but those aren’t represented here. If you read the image, all you get is this:
.-----.-.-..
which could say “word” (.-- --- .-. -..), but it could also say “ammeki” (.- -- -- . -.- ..), or many other things.
To address these issues, let’s make two changes:
(1) Define the width of the image beforehand. This way, as we’re setting down the black and white pixels into rows, we always know where to go back to start a new row, rather than having to guess at the image dimensions. Let’s go with 300 pixels wide for now.
(2) Use an unambiguous encoding system. Binary is a good choice here, because any binary encoding system used by a computer has to be unambiguous: computers need to be able to tell what text is represented from just the zeros and ones without relying on gaps between them. Usually they do this by making each character the same length — if every character is represented by a sequence of 8 binary digits, then you always know where one ends and the next begins.
However, the most common encodings in use — ASCII and Unicode — have some digit sequences that don’t represent actual characters. If we based our system on one of these encodings, then used it to interpret an arbitrary shape, many of the resulting characters would be invisible instructions for a nonexistent teletype machine. So let’s use a custom encoding that only includes characters we want:
Here, some of the characters are 6 bits (digits) long, while others are 7, which might make it seem ambiguous — if you’re given a long string of bits, how do you know whether to look at the first 6 bits or the first 7 to determine the first character? However, I designed this encoding so all the 6-bit characters start with 1, while all the 7-bit characters start with 0, so you can look at the first bit and it tells you how many to read off. That way you can always tell when one character ends and the next begins.
To convert an encoding to an image, let’s say that 0 is white and 1 is black. (If you’ve worked with colors on computers, this is the opposite of what you’re used to, but remember that “black” is really just short for “a point inside the shape” while “white” means “outside the shape.” In is 1, out is 0.)
Now that we have this system, let’s encode some longer text. Here’s the UDHR:
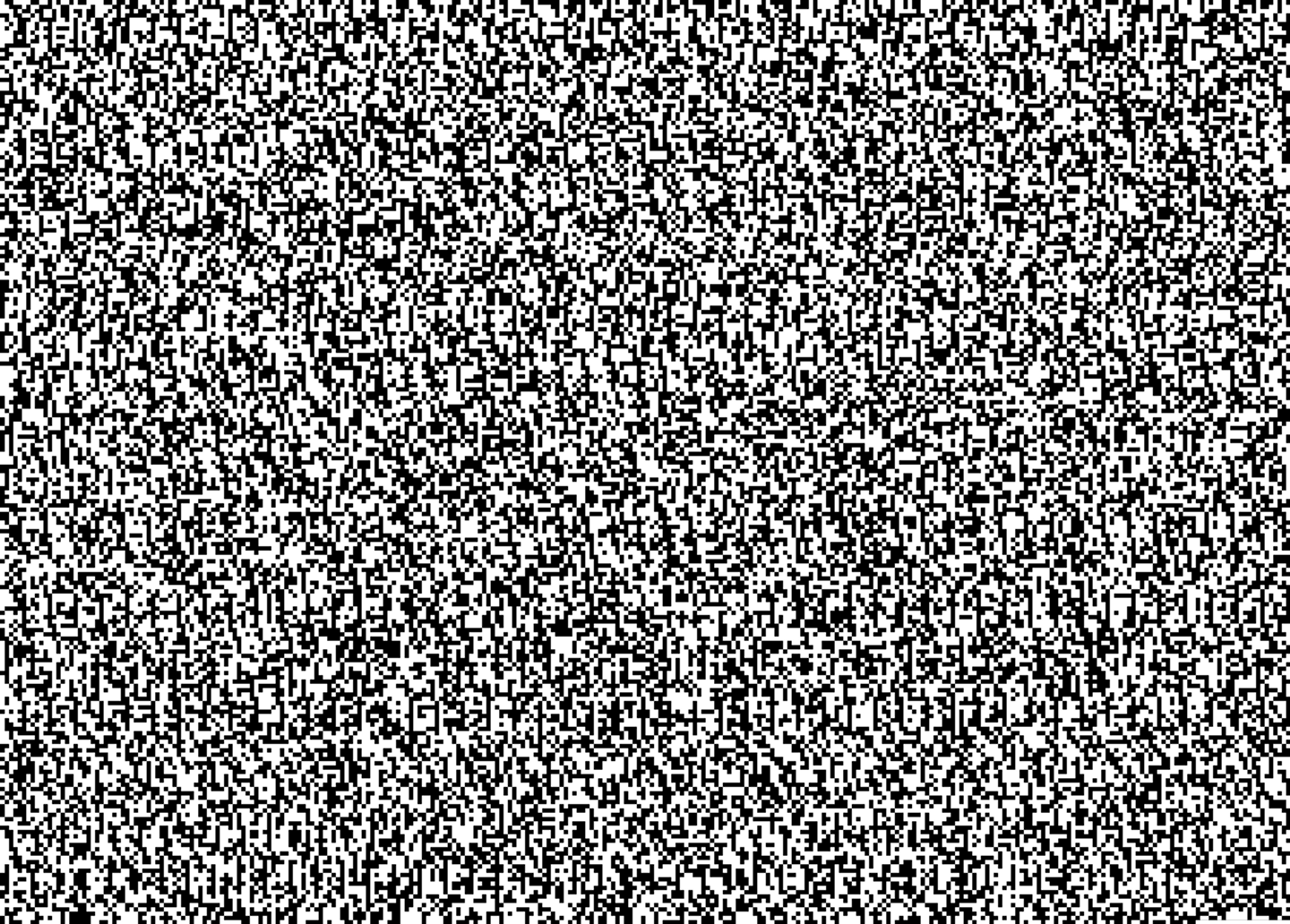
Hmm... that’s not really a shape; it just looks like noise.
Let’s also try going the other way, and convert a shape into text. Here’s what happens when we “read” a circle:

↓
0000000000000000001-----"0000000000000000000000000000000000007-------"00000000000000000000000000000000001----------000000000000000000000000000000000]-----------00000000000000000000000000000000&------------ 000000000000000000000000000000]-------------,000000000000000000000000000001--------------- 00000000000000000000000000007---------------"0000000000000000000000000000&----------------x000000000000000000000000000&----------------- 00000000000000000000000000&------------------ 00000000000000000000000007------------------- 0000000000000000000000001--------------------x000000000000000000000000]--------------------,000000000000000000000000----------------------000000000000000000000003----------------------p00000000000000000000007----------------------"0000000000000000000000]-----------------------p000000000000000000000]------------------------0000000000000000000007------------------------x000000000000000000003-------------------------p00000000000000000000--------------------------p00000000000000000007-------------------------- 0000000000000000000---------------------------p0000000000000000003---------------------------p000000000000000000&---------------------------x000000000000000000----------------------------,000000000000000003-----------------------------000000000000000007----------------------------- 0000000000000000]-----------------------------,0000000000000000]------------------------------0000000000000000]------------------------------p0000000000000007------------------------------"0000000000000007-------------------------------x000000000000001-------------------------------- 00000000000000&-------------------------------"000000000000007--------------------------------x00000000000000---------------------------------p00000000000007--------------------------------- 0000000000000/---------------------------------0000000000000]----------------------------------0000000000000-----------------------------------0000000000003-----------------------------------000000000000]-----------------------------------000000000000/-----------------------------------000000000001------------------------------------ 00000000001------------------------------------x00000000000------------------------------------,00000000000-------------------------------------00000000000-------------------------------------p0000000000/------------------------------------,0000000000/-------------------------------------0000000000/-------------------------------------p000000000&-------------------------------------"000000000]--------------------------------------p000000001--------------------------------------"000000000/--------------------------------------p00000000]---------------------------------------000000003---------------------------------------,00000000/---------------------------------------p00000003----------------------------------------00000000/---------------------------------------,00000007----------------------------------------x0000000&---------------------------------------- 0000001----------------------------------------- 0000007----------------------------------------- 000000]-----------------------------------------0000000------------------------------------------0000003------------------------------------------0000007-----------------------------------------"000000&-----------------------------------------"000000-------------------------------------------000000-------------------------------------------000001------------------------------------------- 00000-------------------------------------------p00000-------------------------------------------,00000--------------------------------------------00000/-------------------------------------------00000--------------------------------------------p0000&-------------------------------------------x0000&-------------------------------------------"0000]--------------------------------------------0000]--------------------------------------------p0003--------------------------------------------,0001--------------------------------------------- 000&--------------------------------------------x000]---------------------------------------------0003---------------------------------------------p000----------------------------------------------000]---------------------------------------------p001---------------------------------------------"000/---------------------------------------------p007---------------------------------------------"001----------------------------------------------x00]----------------------------------------------001----------------------------------------------x00&---------------------------------------------- 01----------------------------------------------"00&----------------------------------------------x01----------------------------------------------- 07----------------------------------------------"00-----------------------------------------------,03-----------------------------------------------p0]-----------------------------------------------01-----------------------------------------------"07-----------------------------------------------x0&----------------------------------------------- 1------------------------------------------------ 3------------------------------------------------0]-----------------------------------------------,0/-----------------------------------------------p3------------------------------------------------p7------------------------------------------------ ]------------------------------------------------0/-----------------------------------------------,3------------------------------------------------,7------------------------------------------------x]------------------------------------------------p&------------------------------------------------ ------------------------------------------------- -------------------------------------------------p-------------------------------------------------p-------------------------------------------------p-------------------------------------------------p-------------------------------------------------q-------------------------------------------------y-------------------------------------------------y-------------------------------------------------y-------------------------------------------------y-------------------------------------------------y-------------------------------------------------y-------------------------------------------------.-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------'-------------------------------------------------y-------------------------------------------------y-------------------------------------------------y-------------------------------------------------y-------------------------------------------------y-------------------------------------------------y-------------------------------------------------x-------------------------------------------------p-------------------------------------------------p-------------------------------------------------p-------------------------------------------------p-------------------------------------------------p/------------------------------------------------1------------------------------------------------"3------------------------------------------------,7------------------------------------------------x]------------------------------------------------p]------------------------------------------------0/-----------------------------------------------,1------------------------------------------------x3------------------------------------------------p3------------------------------------------------0]-----------------------------------------------,0/-----------------------------------------------p1------------------------------------------------ 1-----------------------------------------------"07-----------------------------------------------x0&----------------------------------------------- 0/----------------------------------------------,03-----------------------------------------------p0]-----------------------------------------------00/----------------------------------------------p03-----------------------------------------------00&----------------------------------------------x00-----------------------------------------------007----------------------------------------------x00&---------------------------------------------"003----------------------------------------------p00&---------------------------------------------"001---------------------------------------------- 00]---------------------------------------------,000----------------------------------------------000]---------------------------------------------p001---------------------------------------------"000]---------------------------------------------0003---------------------------------------------p000&--------------------------------------------x0007--------------------------------------------"0000---------------------------------------------0000&-------------------------------------------- 0003--------------------------------------------p0000--------------------------------------------,0000]-------------------------------------------,00007-------------------------------------------"00001-------------------------------------------"00000--------------------------------------------00000&------------------------------------------"00000]------------------------------------------,00000]------------------------------------------,000007------------------------------------------x000007------------------------------------------x000003------------------------------------------p000001------------------------------------------ 000001------------------------------------------ 000000------------------------------------------0000000-----------------------------------------,0000001-----------------------------------------x0000001----------------------------------------- 0000001----------------------------------------"00000007----------------------------------------x0000000]----------------------------------------00000000/---------------------------------------p00000003----------------------------------------00000000]---------------------------------------p00000000/--------------------------------------,000000003---------------------------------------000000000&-------------------------------------- 000000003--------------------------------------,000000000&-------------------------------------"0000000003--------------------------------------0000000000/-------------------------------------0000000000]-------------------------------------00000000003-------------------------------------00000000000-------------------------------------00000000000&-----------------------------------"00000000000&-----------------------------------"00000000000]-----------------------------------,000000000007-----------------------------------x000000000003-----------------------------------p000000000001----------------------------------- 000000000000-----------------------------------0000000000000----------------------------------,0000000000000/---------------------------------00000000000001---------------------------------x00000000000003---------------------------------00000000000000]--------------------------------p00000000000000/-------------------------------,000000000000003--------------------------------000000000000000&------------------------------- 000000000000000-------------------------------p0000000000000007------------------------------x0000000000000000------------------------------,0000000000000000]-----------------------------,00000000000000001-----------------------------x00000000000000000/----------------------------p00000000000000000]----------------------------000000000000000000]---------------------------,0000000000000000007--------------------------- 0000000000000000007--------------------------"00000000000000000007-------------------------- 0000000000000000000]-------------------------,00000000000000000000&------------------------"000000000000000000000-------------------------0000000000000000000007------------------------ 000000000000000000000&----------------------- 0000000000000000000001----------------------- 0000000000000000000000]----------------------000000000000000000000003---------------------,000000000000000000000000---------------------p000000000000000000000000&-------------------"0000000000000000000000000]-------------------00000000000000000000000000&------------------ 00000000000000000000000000&----------------- 000000000000000000000000000-----------------p0000000000000000000000000001---------------- 00000000000000000000000000007--------------"000000000000000000000000000000--------------p0000000000000000000000000000007------------x00000000000000000000000000000001-----------x000000000000000000000000000000000/---------00000000000000000000000000000000000--------p000000000000000000000000000000000000/-----000000000000000000
The white region of the image has long stretches of white pixels, which become a bunch of zeros, and since the sequence 0000000 encodes the character zero the output text has long stretches of zeros. Similarly, the black region becomes a bunch of ones, which results in long stretches of hyphens.
What these examples show is that, while it is possible to represent any shape by listing its pixels row by row, this type of description misses a core fact about how shapes work — the fact that shapes are contiguous blocks of space that are fully black, surrounded by a contiguous block of white space. Because the system so far doesn’t understand this fact about shapes, it uses a lot of redundant characters to spell out all these contiguous blocks when we decode an image. And because it doesn’t understand how shapes work, it doesn’t produce contiguous blocks of space when we give it arbitrary text.
A better process for describing shapes
Resolution Code uses a different way of describing shapes that better respects this principle. It starts by representing an image at a very low resolution, and then adds more and more detail, but only in the places that need detail.
(For the rest of this explanation I’ll be using the word “shape” somewhat loosely — the system we will land on really generates images or compositions, which can be made of many shapes. But the point is that the compositions are in fact made of shapes, rather than a noisy texture of pixels.)
Let’s look at how the system describes this shape/image:

We will start by representing this image at a 2×2 resolution. I’ll overlay a blank 2×2 grid on top of this, with the pixels waiting to be filled in:

Now let’s use the shape as a guide to fill in the pixels. The top left pixel covers a region of the image that’s fully white, so we can color this pixel white:

The top right pixel covers a region that’s partly black and partly white. We need more detail to represent what’s going on here, so we split it into four smaller pixels that we’ll return to later.

We proceed to the next row: the bottom left pixel is fully white, while the bottom right needs to be split:

Now we’ve reached the end of the image. At this point we’ve already defined the left half of this image. But there is the other half that needs more detail. So we go back and start a second iteration, doing the same thing at a smaller scale. As before, we read from left to right, then top to bottom. The first one needs to be split:

The second one is fully black:

And so on:

As we go, we keep track of what we did with each pixel. In the first iteration earlier, the first pixel was white, the second was split, the third was white, and the fourth was split. In second iteration that we just finished, the instructions were splitblacksplitblacksplitsplitwhitewhite .
A third iteration: as we go through the remaining blue undefined pixels in the above image, the shape indicates that the next instructions are sbsbsbsswssbwwss .

We can keep doing this indefinitely, describing the shape in ever-increasing detail and producing an ever-growing sequence:
With only this sequence, you could reconstruct the shape in as much detail as you’d like.
So now we have a system for converting back and forth between shapes and sequences of B/W/S instructions. To convert between shapes and text, we could come up with another encoding that represents text as sequences of B/W/S instructions, like how binary represents text as sequences of 0/1 bits. To convert a shape to text, we’d describe the shape using a B/W/S sequence like we just did, and then use the encoding to interpret the sequence as text. To convert text to a shape, we’d first encode the text as a B/W/S sequence, and then use that B/W/S sequence as instructions to produce a shape.
Before we go ahead and define this encoding, let’s test whether such a system would actually produce good-looking shapes. We can assume that whatever encoding we make would have about an even mix of b, w, and s, so we can just use a randomly generated sequence of instructions to get a sense of what shapes would result:
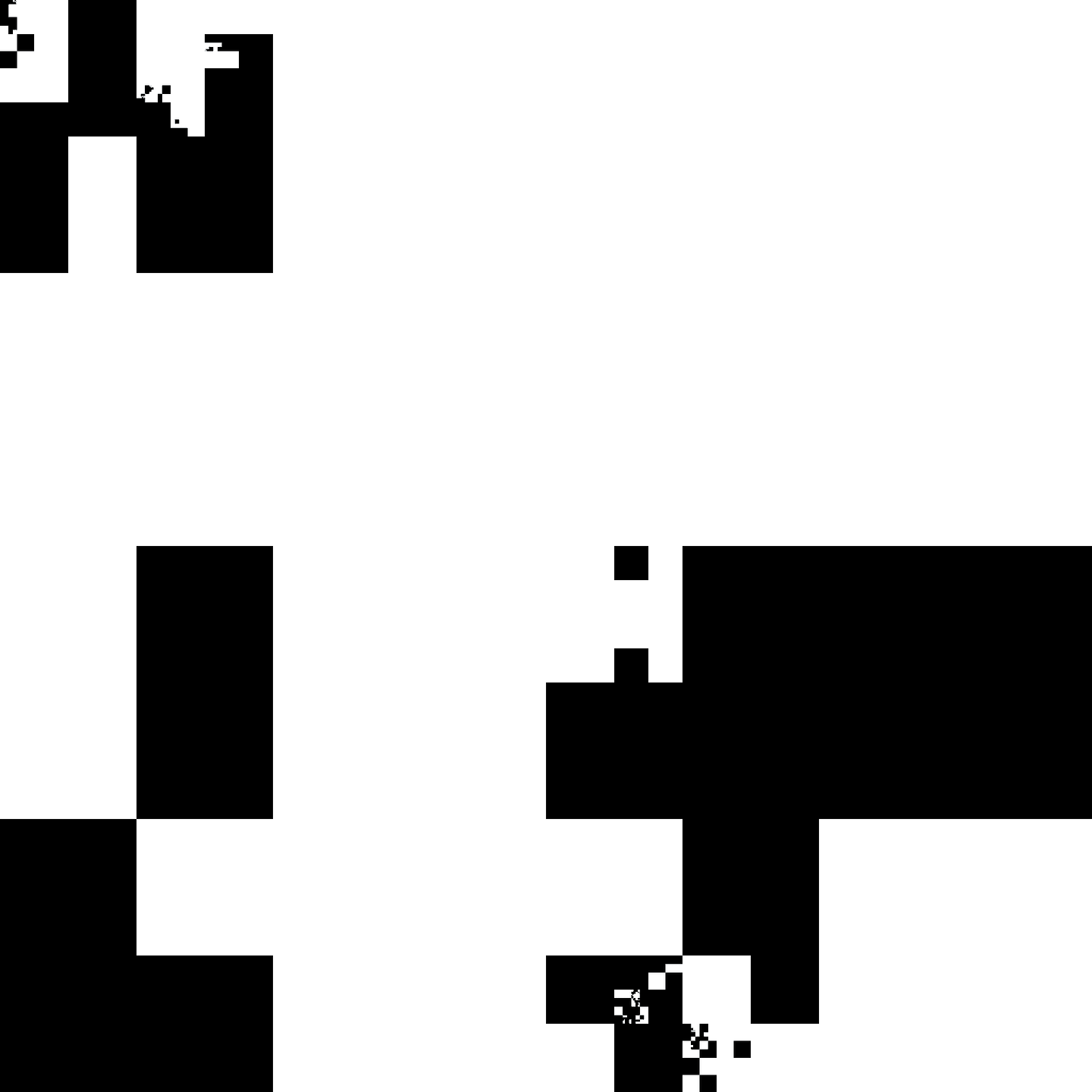
This is better than the noise-like image we had earlier, as there are clearly defined clumps of black surrounded by an expanse of white — but it’s too blocky. We don’t want the output of the system to look like a bunch of squares stuck together; we want it to look like a more organic shape. So we need to tweak things a bit.
Generating better shapes
We have built a system that “understands” one fact about shapes — that they include contiguous black regions surrounded by contiguous white regions — but the fact that the output is so blocky indicates that there is something else it needs to understand. To figure out what, let’s look at the first four iterations that resulted in the above image:




For comparison, here are the first four iterations of the earlier shape:




Notice a key difference here: in the latter sequence, the one that describes a normal-looking shape, black and white never touch. There is always a buffer of undefined, split pixels between the black region and the white region. In the the image we just generated, however, black and white pixels are touching all over the place, resulting in the many hard edges and right angles.
So let’s see what happens if we impose a rule that black and white pixels are not allowed to touch each other. To test how this would look, we can still randomly select what to do with each pixel, but we now have to restrict what options are possible based on what a pixel is touching. For example, let’s say we’re selecting what to do with this pixel:

Because this pixel is touching white, it can’t be filled in black — it can only be white or split. So we randomly select between those two options.
Similarly, this one is touching black, so it can only be black or split:

This one is touching both black and white, so it can only be split:

And this one is touching neither black nor white (the corners don’t count), so all three options are possible:

Now let’s generate a shape using these rules. For each pixel, we look at its neighbors to figure out which of the three options is allowed. Then we select one of those allowed options at random. Here’s what we get:

Now we’re getting somewhere! This looks much more like a shape you’d find in nature.
However, this looks like it’s only part of a larger shape that is cut off by the edge of the frame. I’d rather have shapes that are completely enclosed by the frame, with a similar level of roughness all the way around. To achieve this, we will disallow any pixel on the edge from being black. (You could imagine that the image is surrounded by a white frame, and since black can’t touch white, none of the pixels on the edge can be black.)
Here’s what this produces:
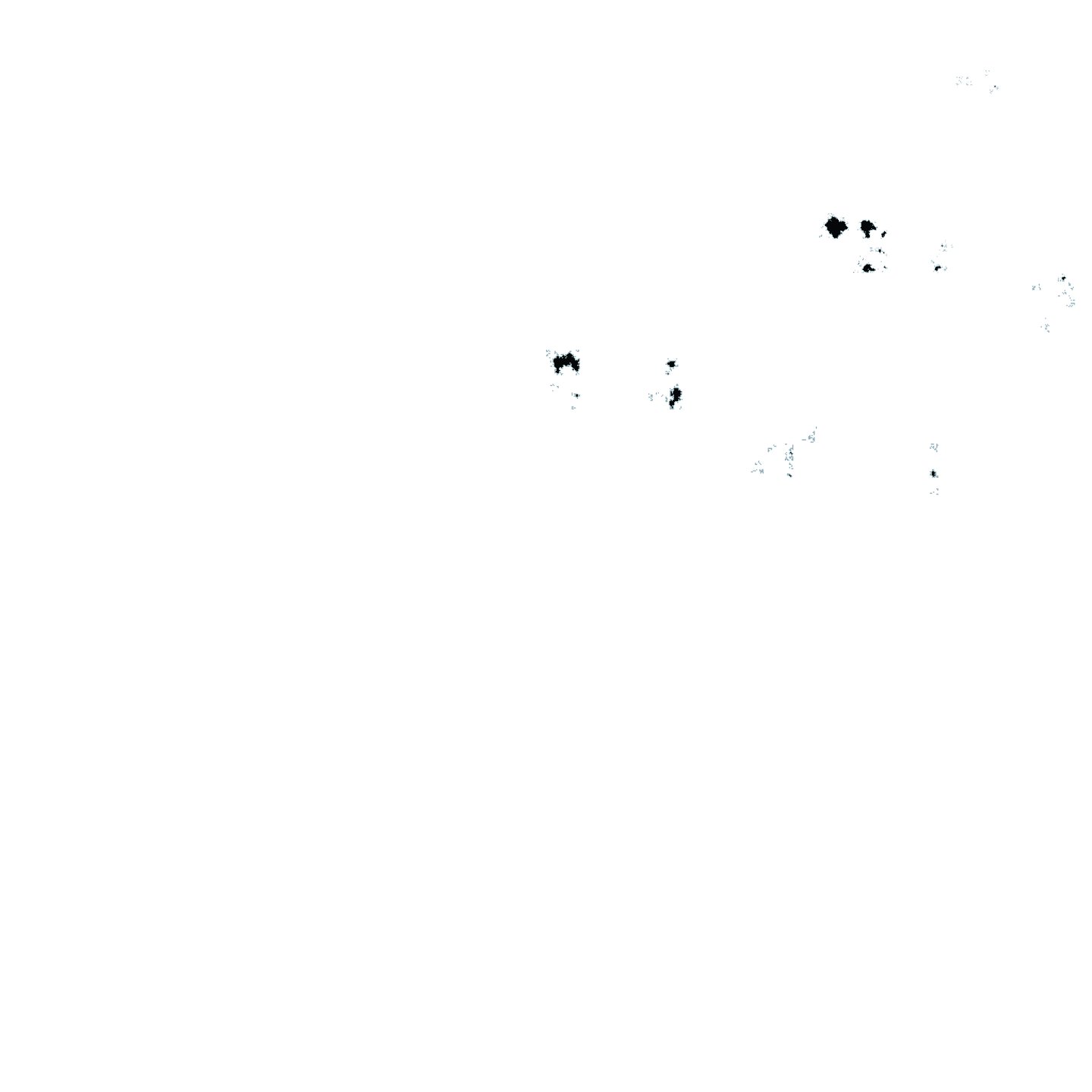
While these shapes do lack the hard line from before, they’re way too small. Why is that?
Consider how this is generated. We start with four pixels, none of which can be black because they’re all touching the edge. So each of them has an equal chance of being white or split. That means that, on average, two out of four of them will end up filled white — and so, after just one iteration, half of the image is set to be white, which severely limits how big any eventual black shapes can be.
Then, in the split pixels of the next iteration, the same thing takes place at a smaller scale. Most of these pixels will still be touching white on at least one side, so each of them has a ~50/50 chance of being filled white — and so now after two iterations, on average, only a quarter of the space is left open to ever have a black shape. Black pixels can only show up in the unlikely places where all four neighbors happen to be split, which often doesn’t happen until many iterations in when the pixels are small.
To fix this, let’s try weighting the random generator so that split and black are chosen much more often than white:

This does create bigger shapes — but it’s back to looking more blocky. There is still a buffer of undefined pixels along the edges between black and white, but a lot of those edges are straight.
So it seems that a weighted generator is better for making bigger shapes, but an unweighted generator is better for making more natural shapes. As a compromise, let’s start by using a weighted generator for the first 20 instructions, but then switch to unweighted afterward. The weighted generator carves out a lot of space that black can go in, and then the unweighted generator takes over to make better-looking details. Here’s what this produces:

This feels satisfactory to me. So now we go back to the original goal:
Using the shapes to encode text
What we have so far is a way to describe an image using a sequence of B/W/S instructions, with some limitations on which instructions are allowed in each place. Now we need a way to use text to produce such a sequence of instructions.
Earlier we had considered encoding each character as an instruction sequence — say “A” is whitewhitewhitewhite , “B” is whitewhitewhitesplit , and so on — and then read off these instructions to produce a shape. But as we saw, that sequence will put black and white pixels next to each other, producing blocky shapes. That’s why we added the rule that black and white can’t touch.
So perhaps we could just skip over any instruction that isn’t allowed. For example, if we had a sequence starting with whitesplitblackwhitesplit :
- The first instruction is white, so color the top left pixel white.
- The next instruction is split, so split the top right pixel.
- The next instruction is black. But we can’t color the bottom left pixel black, because it’s touching a white pixel (and the edge). So ignore that instruction and use the next one instead, which tells us we should fill it white.
- The next instruction is split, so split the bottom right pixel.
The result:

This method — encode characters using instruction sequences, and then just skip the instructions that aren’t allowed — works for generating shapes based on text. But it doesn’t encode shapes into text, because we can’t recover the text that was used to generate a shape. In the above example, if you were just looking at the shape and reading off the instructions from it, you’d get a sequence starting with whitesplitwhitesplit , and you’d have no way of knowing there was a skipped black instruction in there. In fact there could be any number of skipped instructions that you have no way of recovering, and so this image could represent any number of possible texts. There’s no way of knowing what it was supposed to represent.
So it seems that going directly from letters to instructions won’t work. Instead we will go back to representing letters using binary digits, and then interpret those binary digits as instructions — but interpret them differently depending on the context. Here’s how this will work:
If a pixel is touching white, there are two options for what instruction to use: white or split. So we will look at the next bit in the binary sequence and use it to select the instruction: 0 for white, and 1 for split.
Similarly, if a pixel is touching black, we’ll say that 0 is split and 1 is black.
If a pixel is touching both white and black, then the only allowed instruction is split. So there’s no need to use any bits to tell us what to do — just split the pixel.
If a pixel is touching neither white nor black, then all three instructions are possible. There’s no way to choose between three items using a single bit, since a bit only comes in two states. So we need to do something more complicated:
- If the next bit is 1: black
- If the next bit is 0, then look at the bit after that one as well:
- If these next two bits are 00: white
- If they are 01: split
(For these purposes, if a pixel is touching the edge, that counts as touching white.)
If you are decoding a shape, then for every pixel, consider the context of the pixels it’s touching to determine what bits (if any) will be used to represent it. For example, if you encounter a pixel that you need to split, then it can be represented in four different ways depending on which of the above rules is applicable:
- If it is touching a white pixel (or the edge), write down 1 as the next bit.
- If it is touching a black pixel, write down 0.
- If it is touching both white and black, don’t write any bits.
- If it is touching neither white nor black, write 01.
This set of rules allows the system to generate more natural shapes while still preserving the text unambiguously. However, at the moment the shapes would be too small. Earlier, when we were randomly generating shapes, we fixed this by weighting the random generator to select black and split more often at the beginning of the sequence. How can we do this here?
I designed the rules above so that a 1 will always create the most opportunities for black pixels: if it’s possible to make a pixel black, 1 will do that; otherwise it will split the pixel, so at least part of it might be black. So we need the beginning of the sequence to have a lot more ones than zeros. To achieve this, we can create an alternate text encoding that uses many more ones than zeros, and use this weighted encoding for the first few characters. I am still figuring out the best design for a weighted encoding that does everything I want it to — produce large enough shapes while still creating good variety, and still allow any text or any shape to be interpreted. The image at the beginning of this page was generated using one of these encodings I was testing.
Further adjustments
There are a few more changes necessary to make sure the system works as we want. Some of these are things I have already done, while some are things I am considering doing in the future. Some of these descriptions get a bit more technical, but they are not necessary for understanding the core ideas of the system.
Consider the following two situations:
- A pixel gets set to black.
- A pixel gets split into four subpixels, and then in the next iteration, all four of those are set to black.
Both of these situations produce the same result: a black square. There’s no way of knowing which was the case just by looking at it. So if you’re decoding an image, any pixel that you interpret as black could also be this other thing. (The same is true for white.) Therefore any image could be interpreted in many different ways — so we haven’t gotten rid of ambiguity after all.
To address this issue, we will add an additional rule: the four subpixels of a split pixel cannot be all black or all white. This means that if three out of four of them have been set to the same color, the last one must be split. This is similar to the situation where a pixel is touching both black and white: there’s only one possible thing to do with this pixel, so you don’t need to use any bits to determine it.
This rule deals with the last bit of ambiguity. Now, if you are converting from an instruction sequence to an image, a split pixel is guaranteed to contain both black and white in the final image, and so it will be interpreted correctly as split.
Let’s say you’re encoding some text whose binary string starts with 00001. The first 0 tells us what to do with the upper left pixel: out of the two options of white and split, it chooses white. Similarly, the next three zeros choose white in all the other pixels. And now what do we do with the 1? There are no more undefined pixels that could be split or colored in. So in the current rules, it’s impossible to represent this text.
To address this issue, we add another rule: if there is only one undefined pixel left, it can only be split, not colored in. This ensures that there will always be places to encode the next digit.
Let’s say we wanted to take that tree from earlier and convert it to text:
This shape is contained in a rectangular frame, while Resolution Code is only able to interpret shapes in a square frame. So to start interpreting it, we can make the frame square:

But that’s not the only way to put this shape in a square frame. We could also frame it like this:

Or in infinitely many other ways. Every choice of framing would result in a wholly different text. Is this what we want?
If we consider the system to be one that represents compositions of shapes in a square frame, then this is fine. These two are different compositions. However, if we want it to represent shapes — with no reference to a frame — then this is undesirable. We want there to be just one possible way to interpret any shape.
My original intention was the latter. So let’s impose a rule that, when preparing a shape to be interpreted by Resolution Code, it will framed as tightly as possible, and it will be aligned either to the top of the frame (if it’s wider than it is tall) or to the left of the frame (if it’s taller than it is wide):

(This still allows the shape to be rotated to create a new framing, but I will call this good enough.)
Because there is now only one way to frame a given shape, we don’t have to put it in a frame at all to know how to interpret it. So the system is now, more truly, dealing with shapes and not images.

But now this introduces a new source of ambiguity. Say you encode some text and it produces this image:

Ideally we wouldn’t need the frame for this shape to keep its meaning. So we remove the frame:

But now, if someone were to interpret this shape, they would follow the framing rules and frame it like this:

And that would produce a totally different text. The problem derives from the fact that we decided the system should only represent shapes framed in a certain way, but at the moment it can still produce shapes framed in other ways.
To ensure that it only produces shapes framed according to the rule — as tightly as possible, and aligned to the top or left — we can add another rule. To figure out what the rule is, consider that:
- If an image is wider than it is tall, it should touch the left, right, and top edges of the frame.
- If an image is taller than it is wide, it should touch the top, bottom, and left sides of the frame.
- If an image is equally tall and wide, it should touch all four edges of the frame.
So to ensure that the resulting shape has one of these properties, we need to make sure it touches the top, the left, and at least one of the bottom or right edges. So we’ll add this rule: a pixel is not allowed to be made white if that makes every pixel on the top edge white, or if it makes every pixel on the left edge white, or if it makes every pixel along both the bottom and right edges white.
At the moment, this system does not usually produce a single shape, but rather a composition or archipelago of shapes. I am fine with this behavior: the fact that it can produce a composition of shapes also means that it can interpret a composition of shapes, and I like that it has that flexibility. However, if you wanted to ensure that the system only produces a single shape, you could add a new rule: a pixel is not allowed to be white if that would cause two black regions to be disconnected from each other.
The way this system is designed now, the image is never actually finished — there is always more detail remaining to fill in. It would take an infinite sequence of instructions to fully define a shape. How, then, can this system represent a finite amount of text?
There are two ways we could deal with this:
- Repeat the text indefinitely to create an infinite sequence of instructions.
- Use the text to create an image that contains undefined pixels, and then use some algorithm to find the simplest shape that will read as these pixels. When reading the shape as text, you’d know to stop when the text starts to become gibberish.
So far I have been doing (1), since I haven’t yet designed an algorithm that would allow (2).
In the system as it is now, the first few characters have a huge impact on the shape, while later characters only determine tiny details. It would be nice if every character could have an equal impact. Here’s one way of doing that (a technical summary):
Find an infinite set S of infinite binary strings, with the property that any possible binary string can be produced by XOR-ing together a subset of S. Then any binary string can be defined by listing out all the items of S, and indicating for each one whether that item should be used in the XOR for this string. If we use 1 to indicate that a string should be used and 0 to indicate that it shouldn’t, then we have a new binary string that represents the same information as the original, but where each of the bits depends on many of the bits of the original. If we use that binary string to construct a shape, every character will have a closer to equal impact on the resulting shape.
Part of my goal in designing this system was to allow any shape in one’s environment to be interpreted as text. This system succeeds at that, but the text produced by any arbitrary shape will just be a string of gibberish characters. The only shapes that produce real, comprehensible text are the ones generated by the system. I have been exploring ways to make the system more likely to generate comprehensible text from any shape, without sacrificing the ability to represent any possible text.
When we wanted the system to generate more natural-looking shapes, we imposed some constraints on the image generation process based on our understanding of how shapes work, and then we added rules that interpret the binary sequence differently depending on the context so the shape follows these constraints. It is possible to do the same thing for text: impose constraints on the text generation process based on our understanding of how language works, and add rules that interpret the binary sequence differently depending on the context so the text follows these constraints.
I’ve mostly been able to do this, by implementing an LLM-based text compression algorithm. Like the encoding systems on this page, such an algorithm is a system for representing text using binary data — but rather than always using the same sequence of bits for the same character, it adjusts the encoding based on the context, using shorter sequences of bits to represent blocks of characters (words and parts of words) that make the most sense given the preceding context. This means that normal, meaningful language takes fewer bits to represent than gibberish text — but it also means that normal language is more likely to be produced when the system is used to interpret arbitrary data.
Any existing LLM-based compression algorithm (e.g. FineZip) could be adapted to work with Resolution Code; when I designed this I wasn’t aware of prior work and ended up with a somewhat less space-efficient option based on Huffman codes.
As it is now, the system represents an image by describing it roughly, and then adding more and more detail. I want to see if it could also represent text that way: start with some vague summary of the meaning, and then add more and more detail. With a system like this, you could stop reading the image at any point and still have a good sense of what the text is about.
If we are using an LLM as described above, there might be a way to achieve this. This is a rough idea at the moment, but I’m imagining that rather than representing the text token by token, it would represent text as a sequence of longer and longer summaries, culminating in the full text itself. The largest-scale structure of the shape — the first few iterations of large pixels — would be defined by the shortest summaries, while the more detailed structures of the shape would be defined by the more detailed summaries. With such a system, the visible aspects of the shape would truly reflect the meaning of the text.